Taking Apart Once Human Game Files
Problem
My buddy’s birthday is coming up and he’s really gotten into an online video game called Once Human recently. I played with him for a while and we had a great time!
While considering what to get him for his birthday, I decided that 3D printing a figure from the game would be perfect. However, the game’s models are not publically available. So some data mining needs to happen.
I have never delved into game files before so this will be an interesting adventure!
Solution
I have no idea how to begin, so let’s take a look at the game folder directly.
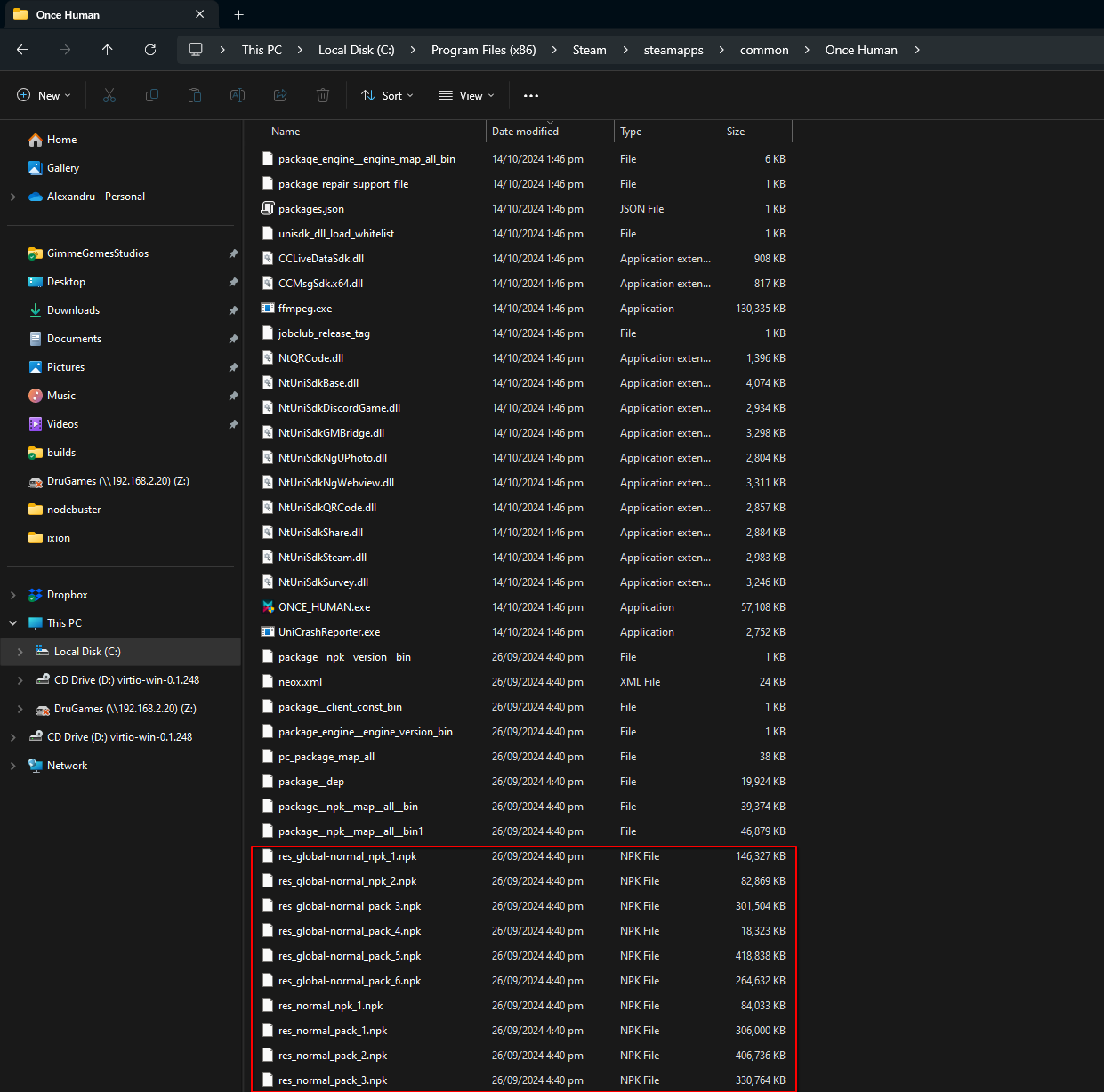
The folder contains a bunch of dlls, the exe, some additional files, and a bunch of .npk files. Additionally, the npk files have names such as res_normal_pack_#.npk. This is most likely the resource format (maybe a compressed format) for all the game assets.
Looking online for some additional assistance, I found some threads/websites that had created NPK Extractors. These extractors would, in theory, take the npk files in the game directory, process them, and spit out something usable. However, this is the hacking community we’re talking about so I don’t feel comfortable running that software without looking deeply at what it does, AND, more importantly, I want to understand how to create such a tool myself. We’re here for the adventure after all!
Researching the file format further, I learned that NPK files are the file type used exclusively in the NeoX engine, which is an inhouse engine developed by NetEase (the game creator).
After some more digging, I found a webforum called Reshax. They have a tutorial collection on reverse engineering and I started looking through it. During the research I learned about something called a binary polyglots and how this kind of file can be created. Polyglots are interesting files that are valid under multiple file format interpreters. This is how you can get a pdf that is an image too. Very interesting, but not exactly relevant.
Magic
One thing that was relevant was the idea that most files specify a file type within the first few bytes of the binary data of the file. So a .zip file, for example, will have ‘PK’ (0x50 0x4B) as the first two bytes. It turns out, zip was designed by Phil Katz and so PK are his initials. These values are called “Magic” signatures and are typically present at offset 0. Some file formats don’t enforce this. A zip file, is actually one of those formats that doesn’t enforce the magic signature. This is because zip files are written from the tail to the head. This was done to minimize floppy swaps (Ange Albertini: Funky File Formats).
Looking at our resource files (res_global-normal_pack_1.npk) we can see it indeed has a unique signature:
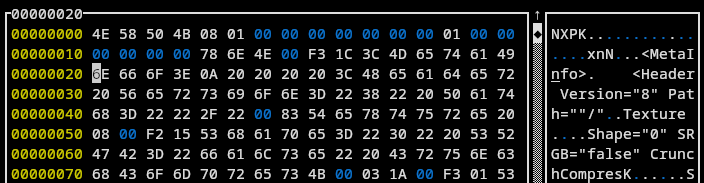
We can see the signature is NXPK. Likely for NeoX Package. (I’m using hexcurses if you’re curious).
Next, I decided to read the Definitive Guide to Exploring File Formats. This was written in 2004, but I doubt there’s been much change since then. This book (60 something pages) has very many useful bits of information that apply specifically to this problem. If you’re interested in my notes you can find them here.
The book recommends using Hex Workshop to explore files. This is a Windows only hex reader with a lot of features. So I swapped to my VM.
I downloaded and installed Hex Workshop. Then I decided to open the smallest once human npk file in the game folder (475 KB).
One of the nice features this program has is color rules. You can specify a color rule for a specific byte sequence and it will change the way that is displayed. I decided to make all nulls easily visible (see image below).
Note: The book mentioned that all these files are archives that store other files. So to avoid confusion, going forward, all the npk files will be called archives, and any “files” specified will be contents of the archive.
Let’s take a look at the header for this archive.
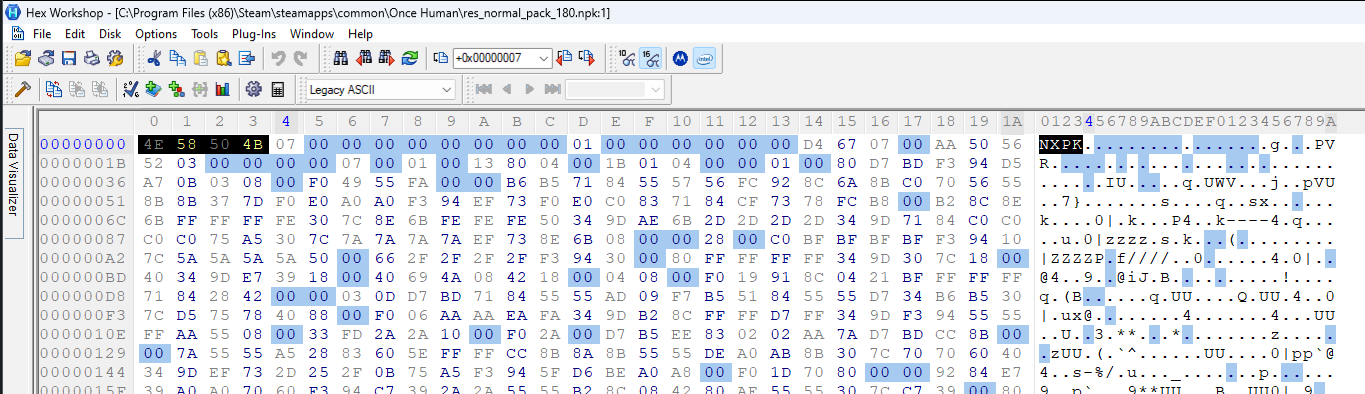
Like in the other archive, res_normal_pack_180.npk has NXPK as the magic. We can highlight those bytes and add a bookmark. I called mine ‘magic’.
File Count?
Immediately after the magic there is a number 0x07. If we assume this is an int16 it points to the 0x01 we see a bit further in the header. But looking back at the first archive we opened (res_global-normal_pack_1.npk) we saw the number was 0x0801 (264 in decimal). So we’re likely right about it being an int16, but it’s not an offset to the 0x01. Let’s open up the largest .npk archive available as well to test our theories out.
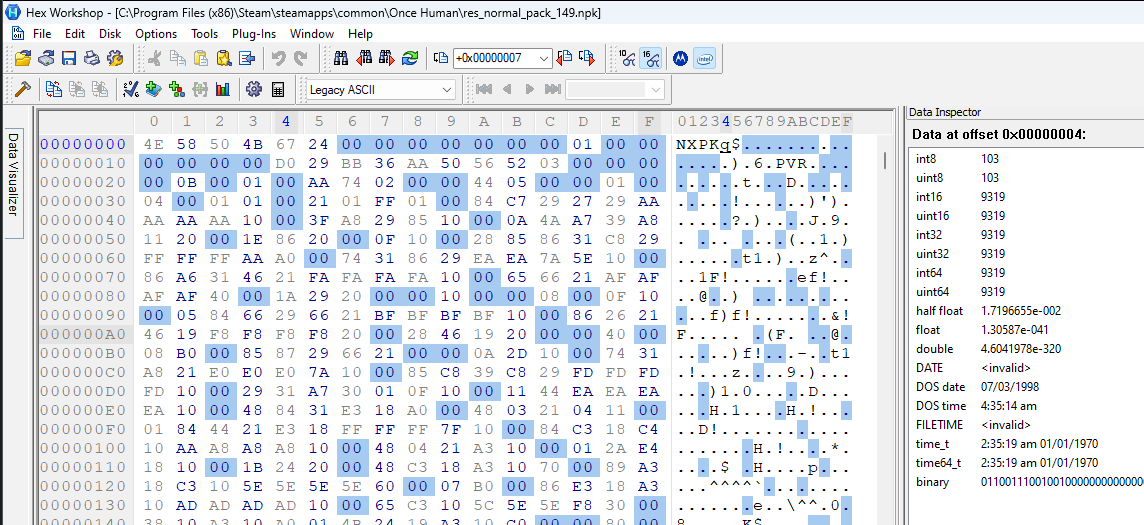
res_normal_pack_149.npk, which has a size of 897,598 KB on disk, has 0x6724 at offset 0x04. This is 9319 in decimal. So clearly this number goes up with archive size. Perhaps it’s meant to represent the number of files stored in the archive? We’ll need to verify this later. I added a bookmark called “File Count?” for this int16 value.
GRAF Version Number?
The next non-null value in the header is the 0x01 at offset 0x0D. This is in the same position in all 3 archives we’re looking at. Perhaps this is meant as a GRAF (Game Resource Archive Format) version number. The starting position is a bit odd though. There are 7 null bytes before it (or 5 if the file count is actually a int32). The position is consistent at least.
Data!
Then all 3 archives have nulls until offset 0x14. To me, the next value looks like an int32. Let’s compare all 3 archives (1: smallest, 2: largest, 3: res_global-normal_pack_1):
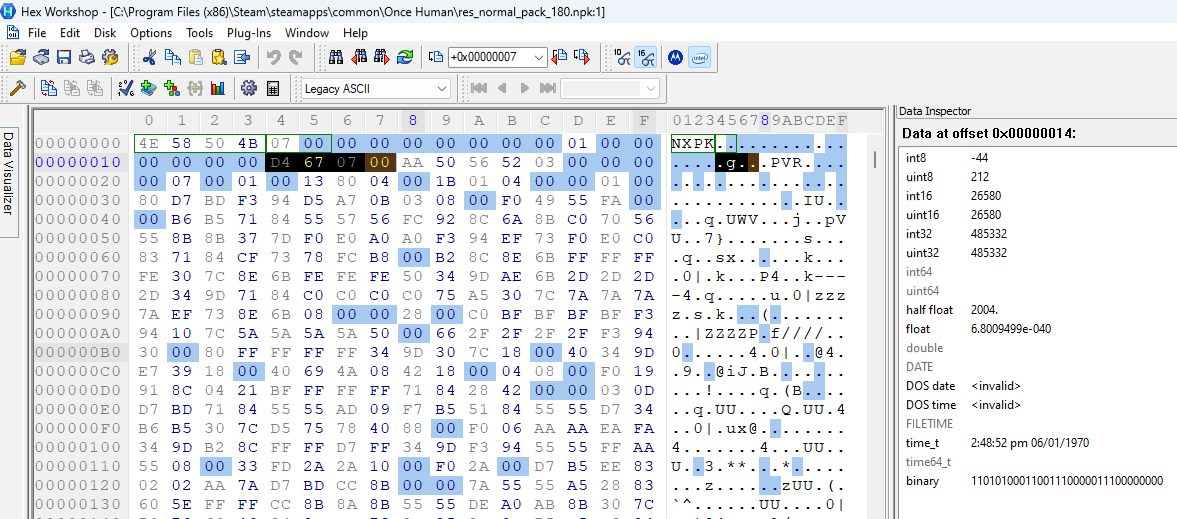
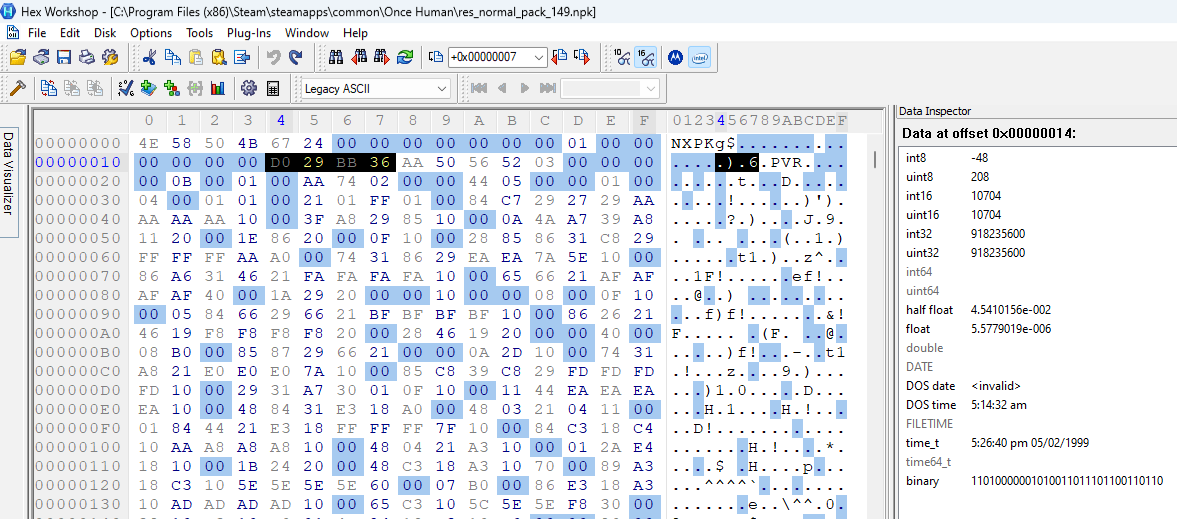
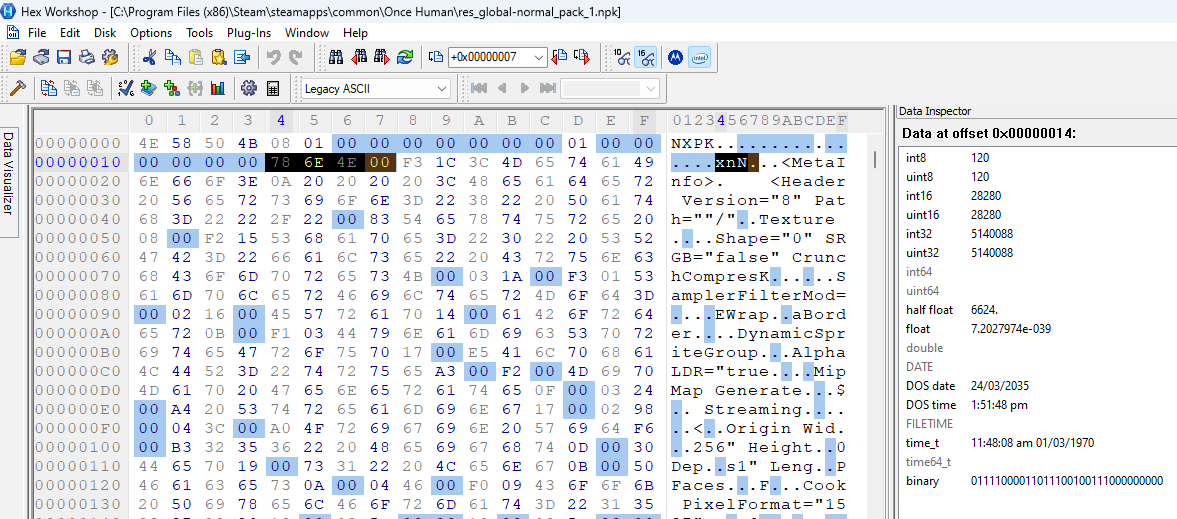
I have no clue what this value is, but I see that the first two archives have a .PVR. shortly after it. Looking up the PVR file format I found this document. Page 9 of this document specifies the metadata format for the file (aka the header). We can see this in the image below:

It specifies that the FourCC values are 'P','V','R',3. Going back to the two archives that have PVR, we can see that pattern at offset 0x19. I think it’s safe to assume that this is actual file data for a PVR file.
The third archive has some completely different values at 0x19 and is then followed by tags that look like some kind of file metadata. Seeing as this isn’t present in the other archives, I would assume that this metadata is specific to whatever file is archived at that location.
Some questions remain:
- What is the
int32before the file data? Is it an offset or a file size of some kind? - Why is there a
0xAAbetween theint32and the PVR file data?
What is the value at the 0x14 Offset?
Let’s see if the value at 0x14 is an offset and jump to that point in in all three archives. This is what we see (same order as before):
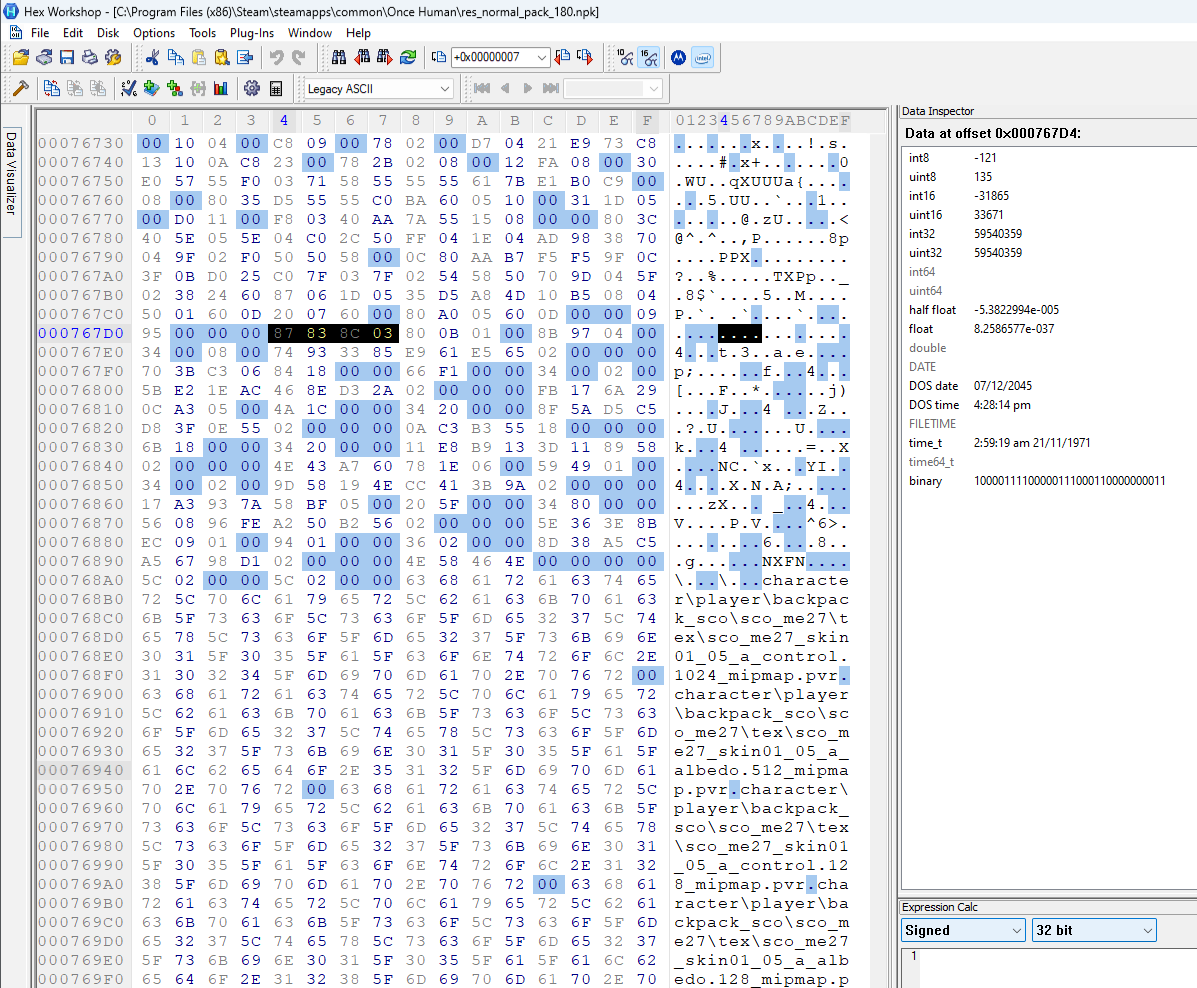
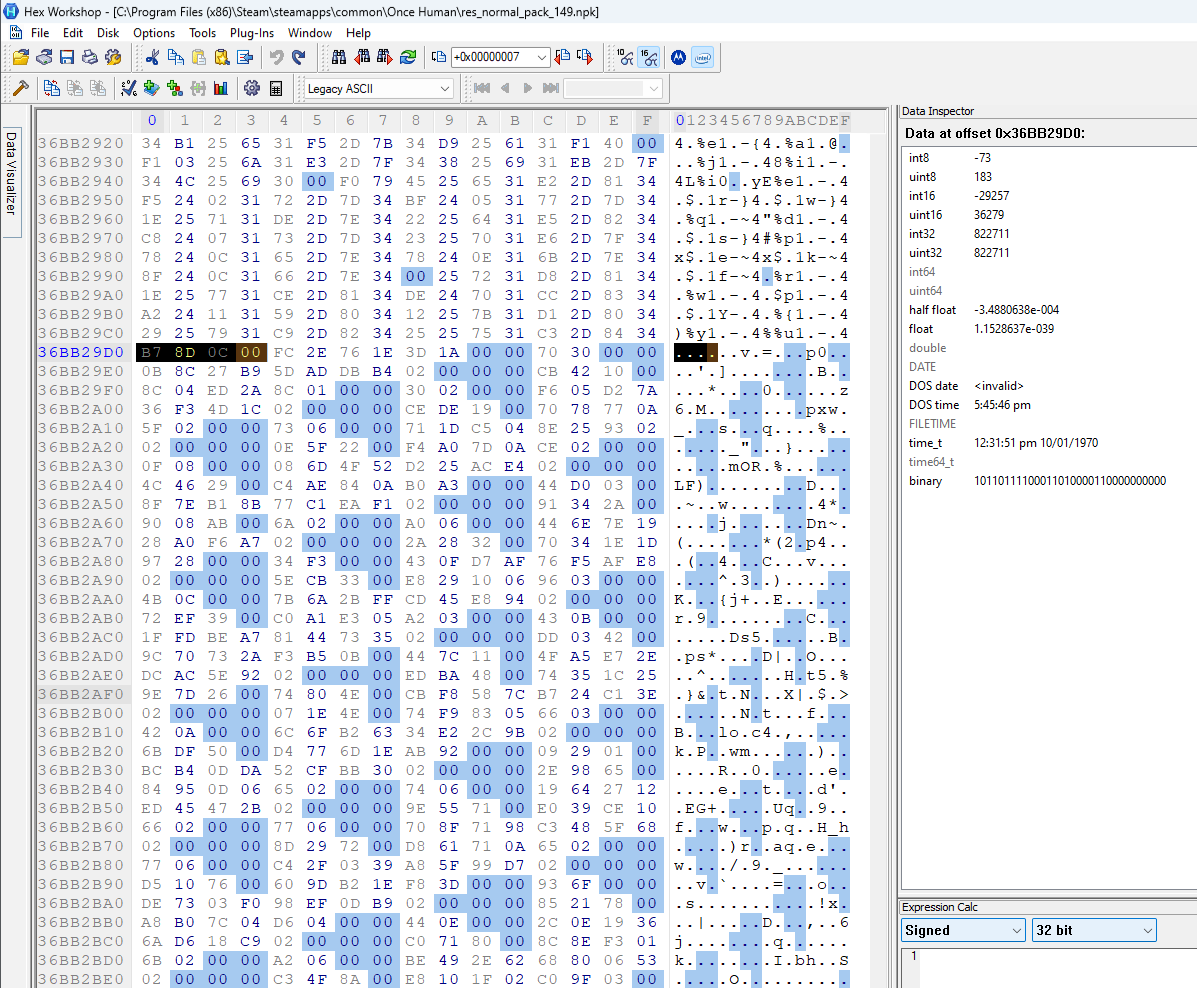
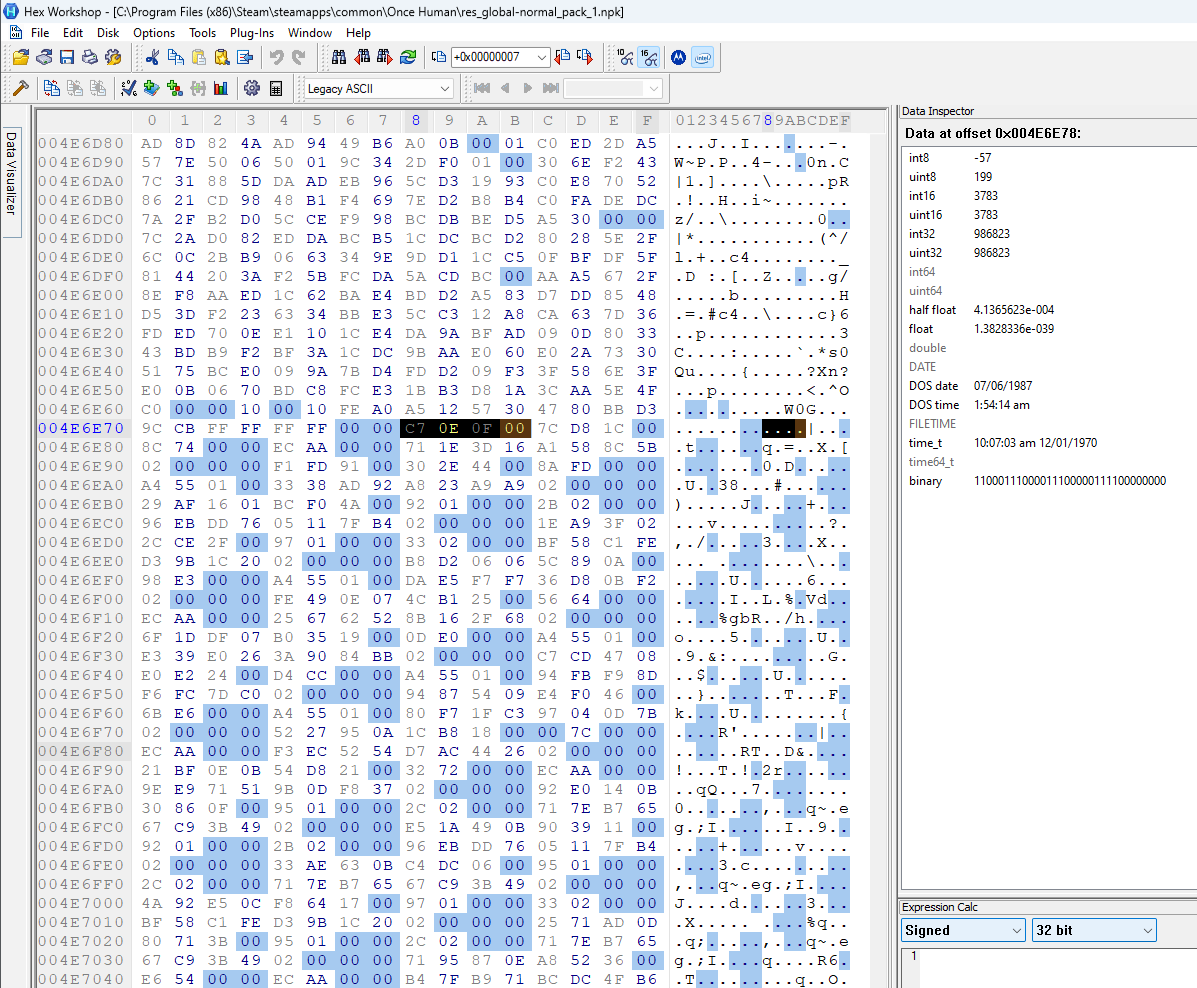
I highlighted the next 4 bytes following the jump. In all three archives we can see a clear change in the pattern of null bytes. It seems that the value at 0x14 is indeed an offset and it points to some kind of arrayed data structure that enforces a padding of some kind.
Additionally, in the smallest archive (the first archive), we can see that after this structure, there is a list of text that looks a lot like file names (and their original path). Once these paths are finished, the archive ends.
The file paths seem to be separated by a single null character (or not separated at all if we include the null as part of a null-terminated string). Additionally, the archive seems to be padded to align to a 4 byte offset. If the last path ends at offset 0x07 6B 00 (with that null byte being the end of a null-terminated string), then the archive would not be aligned properly and 3 null bytes would be added.
Finding the paths like this is quite fortunate. The file paths are easily readable which indicates that the archive is likely not encrypted. The fact that we saw the PVR magic in the file data earlier also supports this claim.
File Count!
Furthermore, we can now validate that the number at offset 0x04 is indeed the file count. By manually counting the file paths, we can see there are 7 different null-terminated strings representing paths. This means that our guess from earlier was likely correct. We will still need to verify with the other archives to make sure this is true. I opened up the second smallest archive and it seemed to follow the pattern as well (11 files in that one).
Analyzing the arrayed structure
I decided to take a look at where the padded structure ends and the file paths begin in the large archive. I noticed there is some ascii text NXFN. This text is also visible in the small archive. I then used the search for text feature of Hex Workshop and found the pattern in the third archive as well.
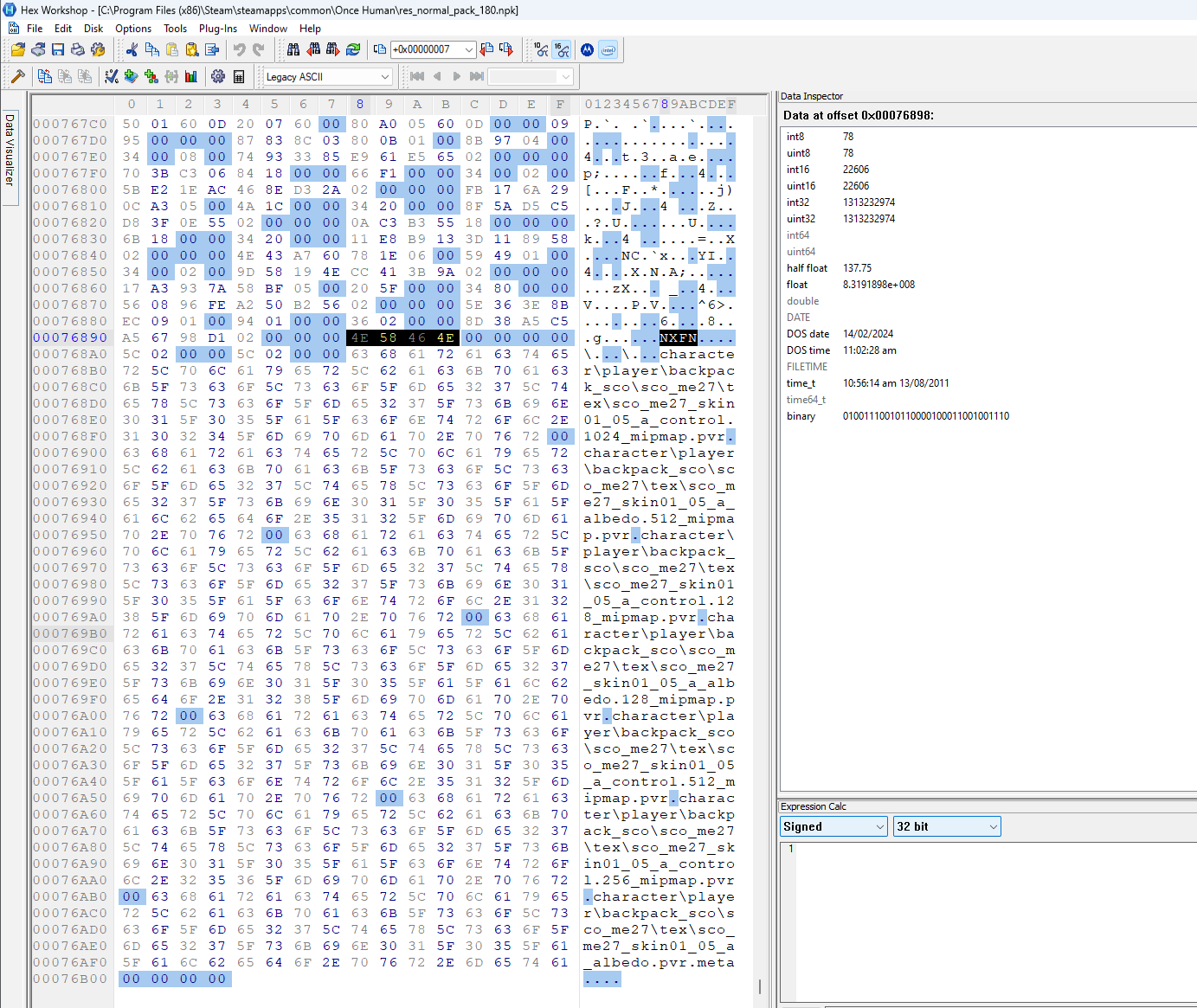
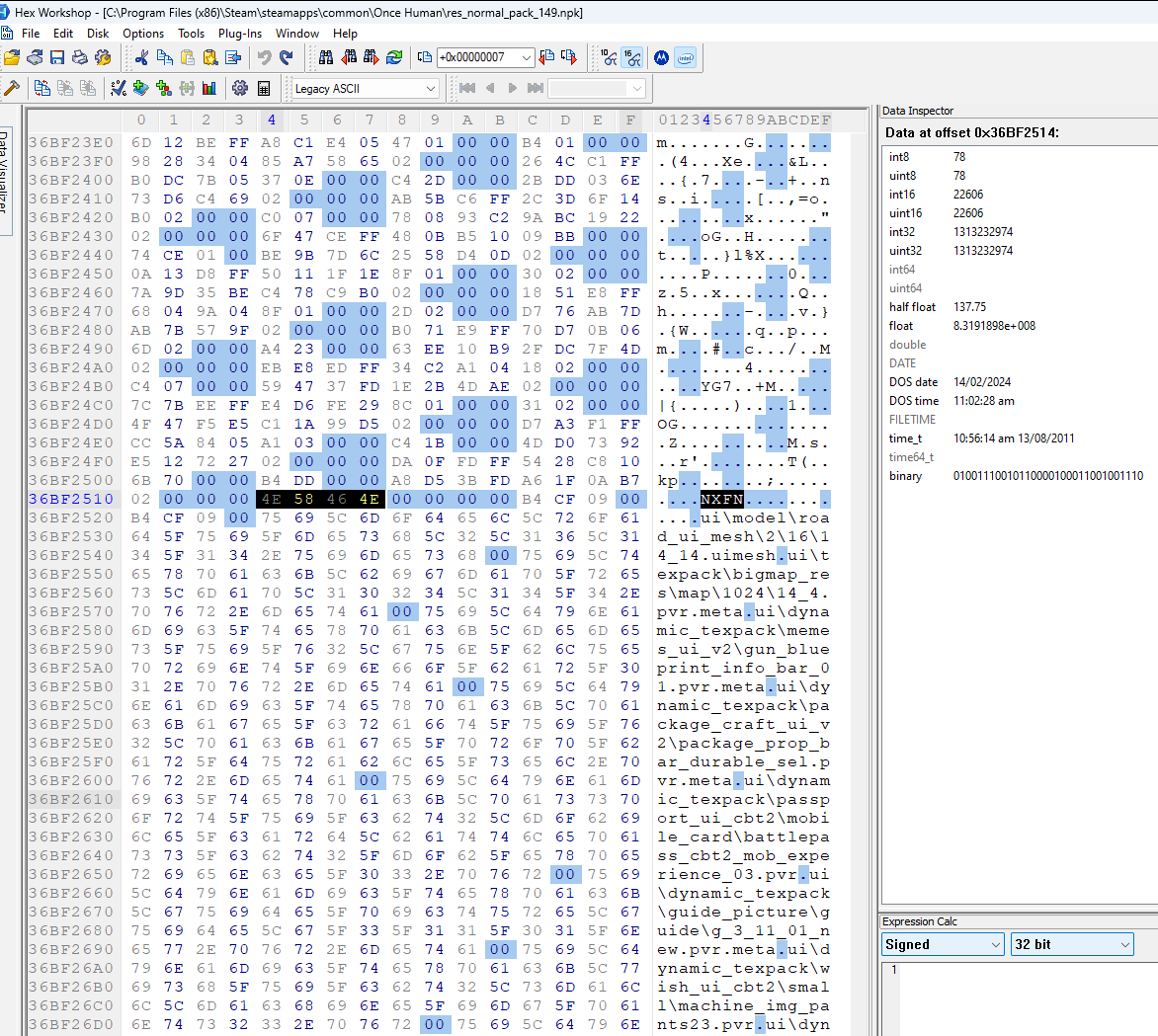
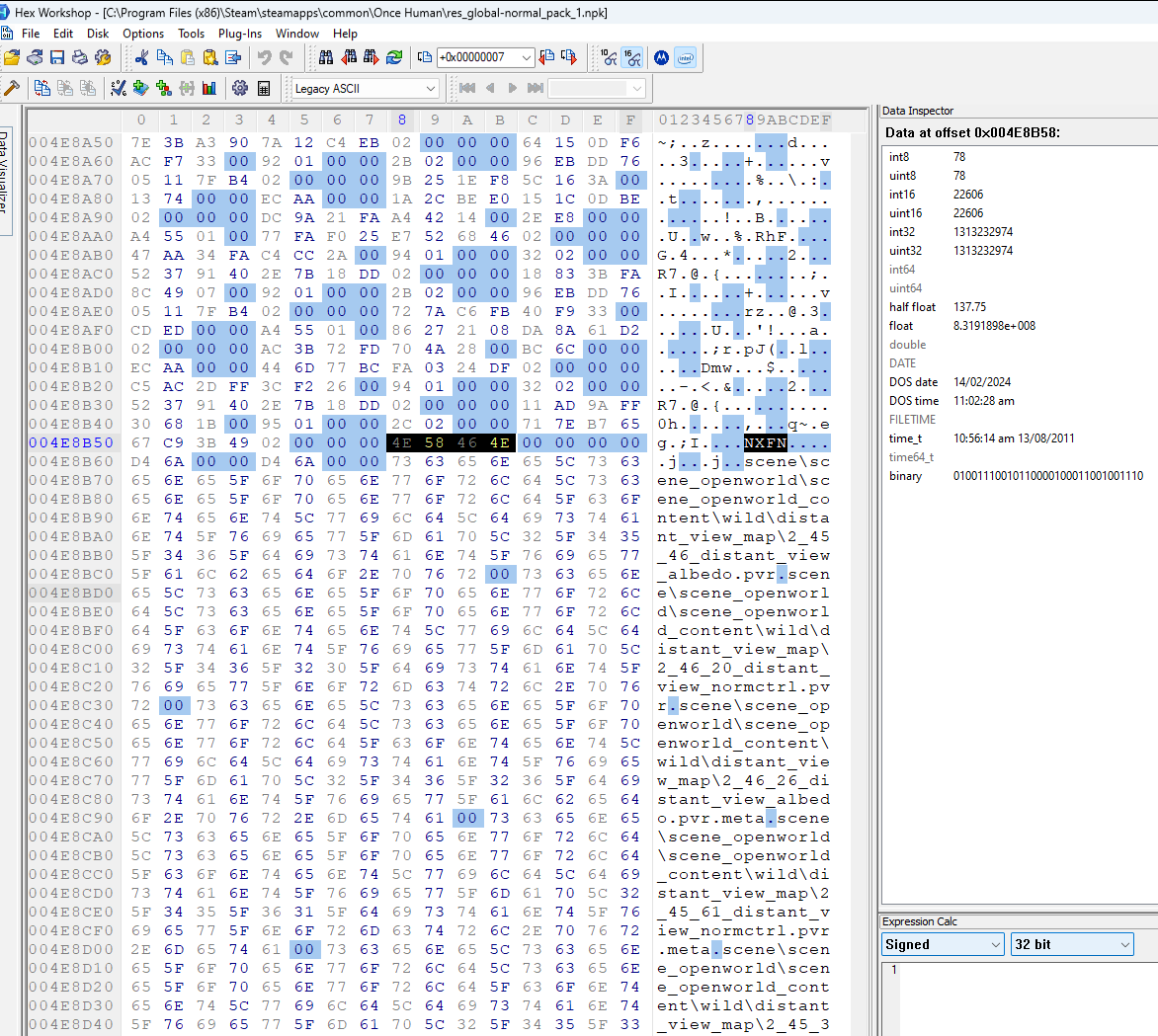
There is another pattern I observed. The NXFN is preceeded by a int32 that has the value 0x2. It also has a 4 byte null following the NXFN. After the 4 bytes, there are two int32 values that hold the same value (different between the archives but the same relative to each other). After these two repeating values, the file paths begin.
I used the jump to feature in hex workshop to jump by a value amount from the current offset. My thinking was the value specifies the amount of bytes in the file path segment. Unfortunately, this didn’t line up perfectly across all 3 archives. It was close but not quite right. Then I decided to use the selection counting feature of Hex Workshop to see how many bytes there are from the start of the file path section to the end of the file. This always matched the repeating number. So that number tells us how much we still have to read until the end of the file. I’m not sure why that value is present twice, but things are weird sometimes.
The big thing to tackle now is the structure that 0x14 points to. Looking at the smallest archive, I noticed that the 0x2 value that preceeds NXFN happens quite a few times in the table. I decided to color code 0x02 00 00 00 to see it more clearly.
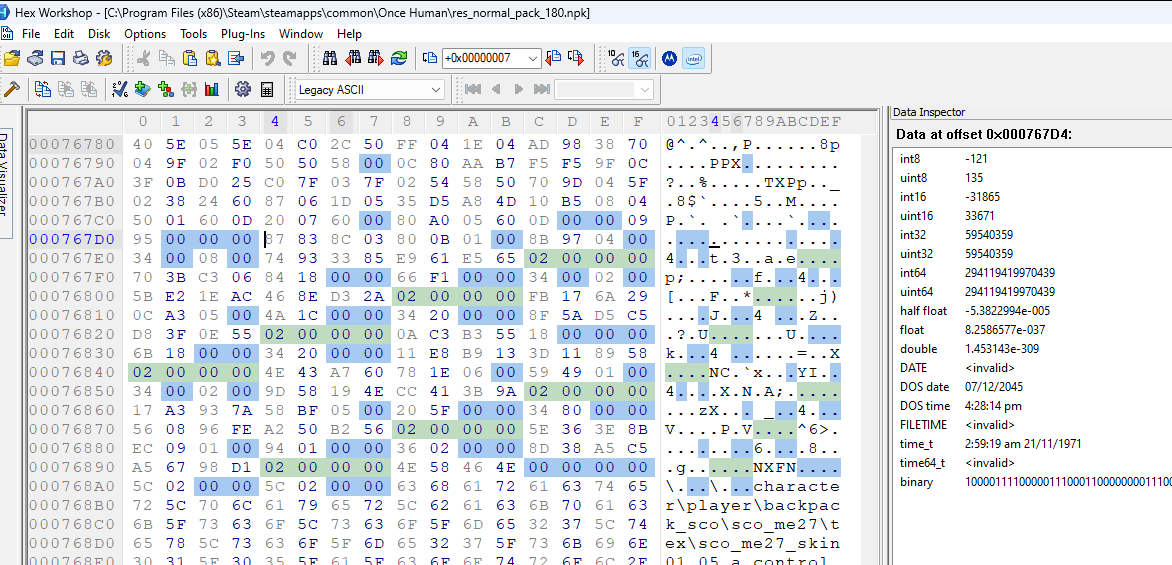
We know we have 7 files in this archive and there are 7 instances of the 0x02 00 00 00 int32 value. So this value must be part of a file directory that specifies properties for the files in the archive. It is likely not part of the NXFN section as I previously thought.
Let’s assume the 0x2 is part of the file structure and not just some kind of separator. From the location pointed to by offset 0x14 to the end of the int32 0x2, there are $7x4=28$ bytes. Some things we may expect to find here are an offset to the file path, and offset to the file data, and a file data size of some kind. Perhaps even a file path length value.
So let’s list out the values for the first file:
87 83 8C 03
80 0B 01 00
8B 97 04 00
34 00 08 00
74 93 33 85
E9 61 E5 65
02 00 00 00
And what we know:
D4 67 06 00 - table address (pointed to by 0x14)
04 6B 07 00 - End of archive
A8 68 07 00 - Start of file path
00 69 07 00 - End of file path
58 00 00 00 - Length of file path (end address - start address)
18 00 00 00 - Start of file data (Assuming 0xAA is part of the file data)
The file paths and addresses:
A8 68 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_control.1024_mipmap.pvr
00 69 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_albedo.512_mipmap.pvr
56 69 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_control.128_mipmap.pvr
AD 69 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_albedo.128_mipmap.pvr
03 6A 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_control.512_mipmap.pvr
5A 6A 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_control.256_mipmap.pvr
B1 6A 07 00 character\player\backpack_sco\sco_me27\tex\sco_me27_skin01_05_a_albedo.pvr.meta
And now I stare at all the number intensely..
Honestly, I’m completely stumped. None of the values seem to mean anything. I was expecting to see a pointer to 0x18 00 00 00 or to 0xA8 68 07 00.
Large Double Table
Let’s try making a table with all the entries to see if there are any patterns between the entries. There are only 7 entries so it should be manageable. I’ll split it into two tables as this page is not wide enough.
| # | Entry 0 | Entry 1 | Entry 2 | Entry 3 |
|---|---|---|---|---|
| 0 | 87 83 8C 03 |
70 3B C3 06 |
FB 17 6A 29 |
0A C3 B3 55 |
| 1 | 80 0B 01 00 |
84 18 00 00 |
0C A3 05 00 |
18 00 00 00 |
| 2 | 8B 97 04 00 |
66 F1 00 00 |
4A 1C 00 00 |
6B 18 00 00 |
| 3 | 34 00 08 00 |
34 00 02 00 |
34 20 00 00 |
34 20 00 00 |
| 4 | 74 93 33 85 |
5B E2 1E AC |
8F 5A D5 C5 |
11 E8 B9 13 |
| 5 | E9 61 E5 65 |
46 8E D3 2A |
D8 3F 0E 55 |
3D 11 89 58 |
| 6 | 02 00 00 00 |
02 00 00 00 |
02 00 00 00 |
02 00 00 00 |
| # | Entry 4 | Entry 5 | Entry 6 |
|---|---|---|---|
| 0 | 4E 43 A7 60 |
17 A3 93 7A |
5E 36 3E 8B |
| 1 | 78 1E 06 00 |
58 BF 05 00 |
EC 09 01 00 |
| 2 | 59 49 01 00 |
20 5F 00 00 |
94 01 00 00 |
| 3 | 34 00 02 00 |
34 80 00 00 |
36 02 00 00 |
| 4 | 9D 58 19 4E |
56 08 96 FE |
8D 38 A5 C5 |
| 5 | CC 41 3B 9A |
A2 50 B2 56 |
A5 67 98 D1 |
| 6 | 02 00 00 00 |
02 00 00 00 |
02 00 00 00 |
Observations:
- Field #3 seems to always have
0x34in the lowest byte. This is true except for entry #6. Looking at the file paths we know that 6 of the 7 files are .pvr files and the remaining file is a .pvr.meta file. Perhaps this field indicates what type of file we’re looking at? Then again, if the field is a fullint32, the value changes regularly so maybe this assumption is completely wrong. - I encountered the
0x18value while entering the values for entry #3. Perhaps field #1 is the pointer to the file data? If so, then the data and the table entries are out of order.
Data offset
Let’s first test that field #1 is the file data offset. If we jump to the other values for field #1, we should see PVR3 somewhere near the file data start. Below are the jump positions specified by field #1 for each of the file entries in order:
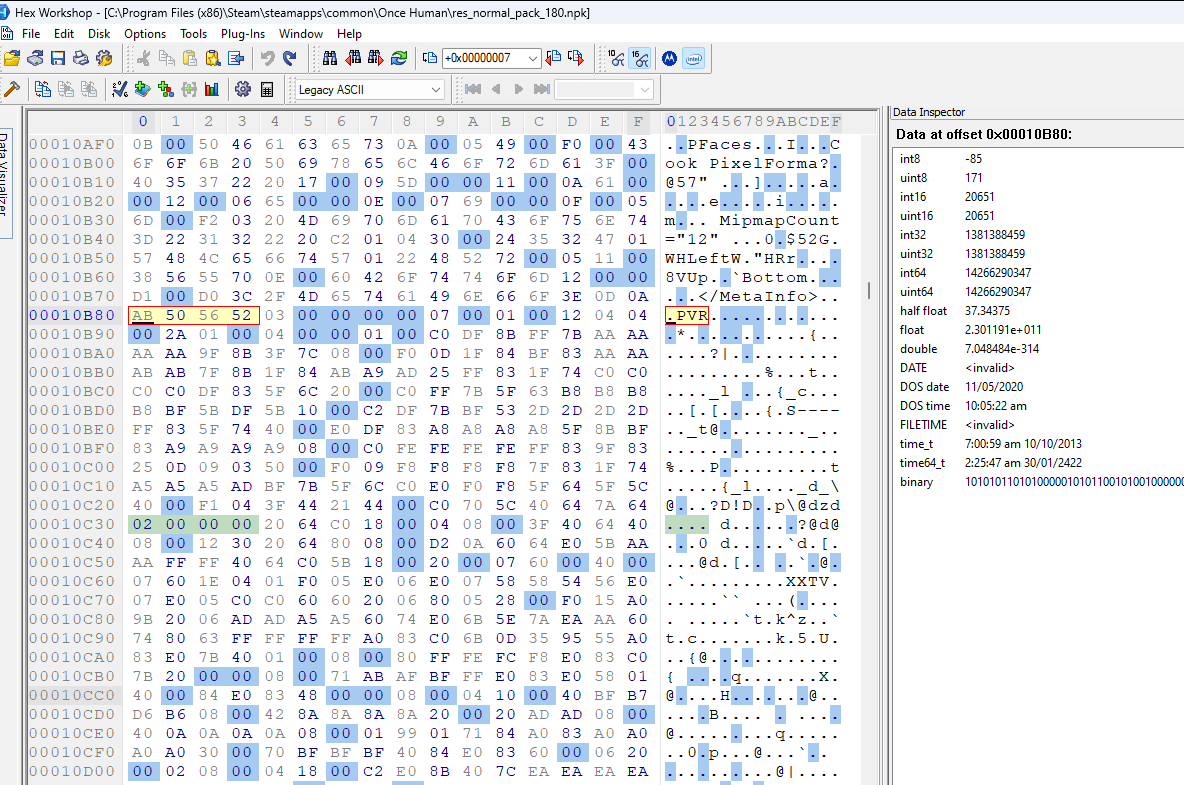
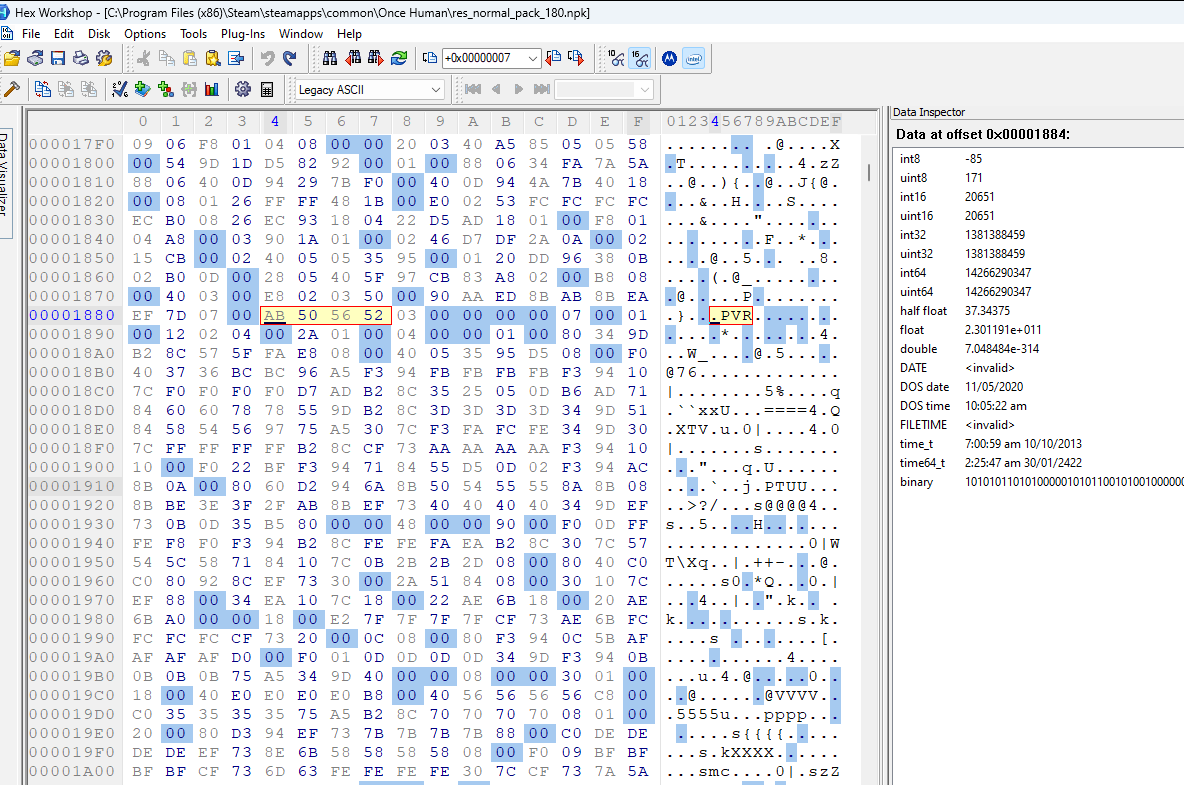
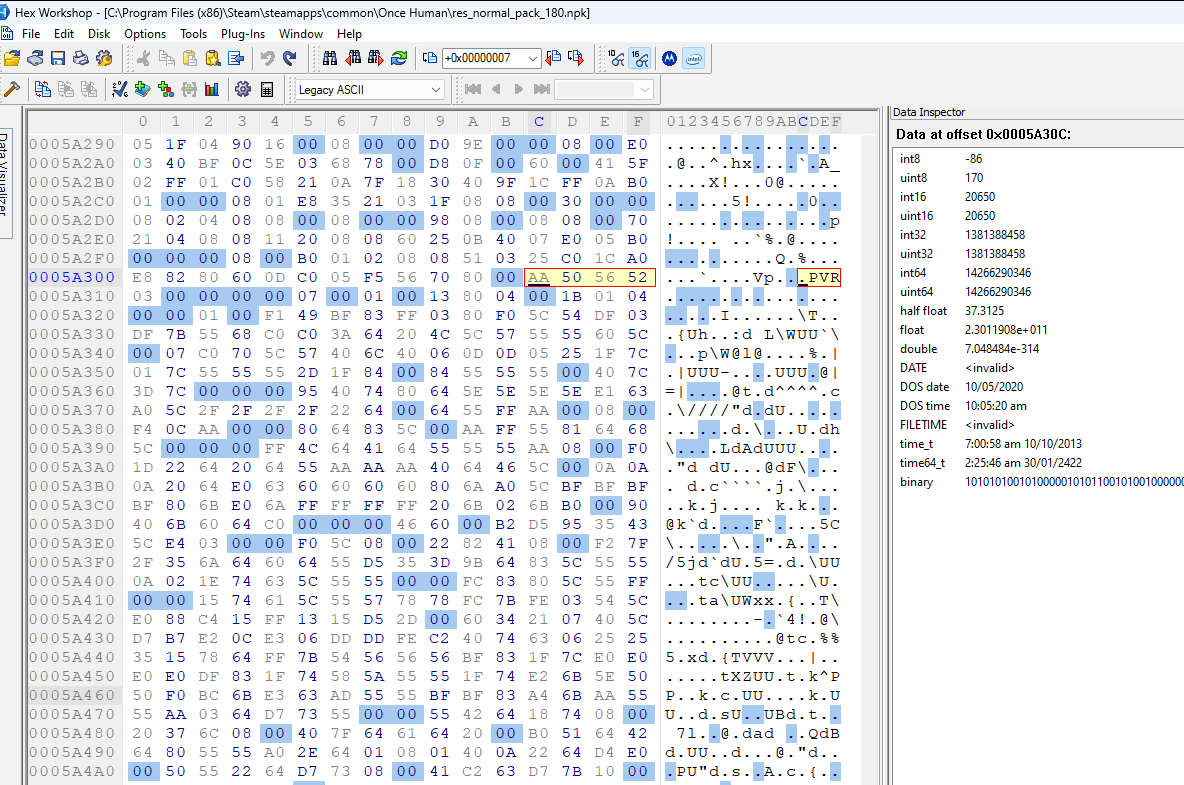
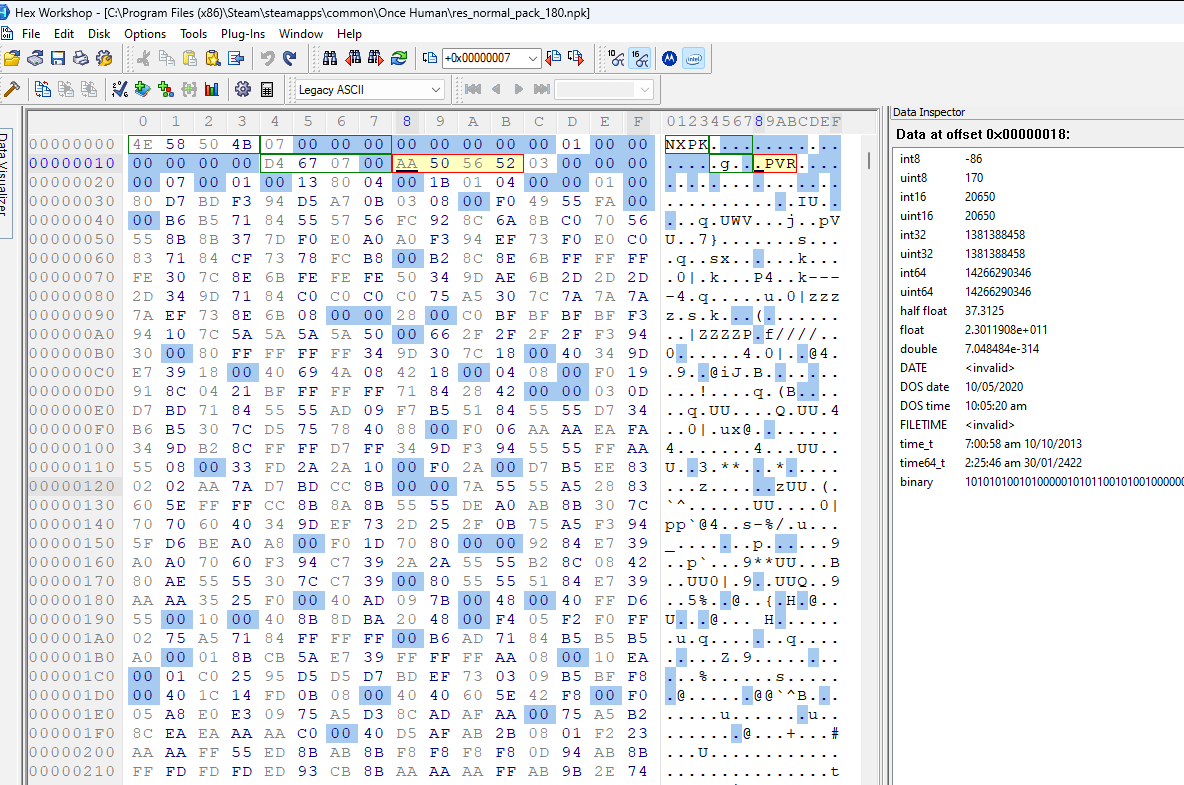
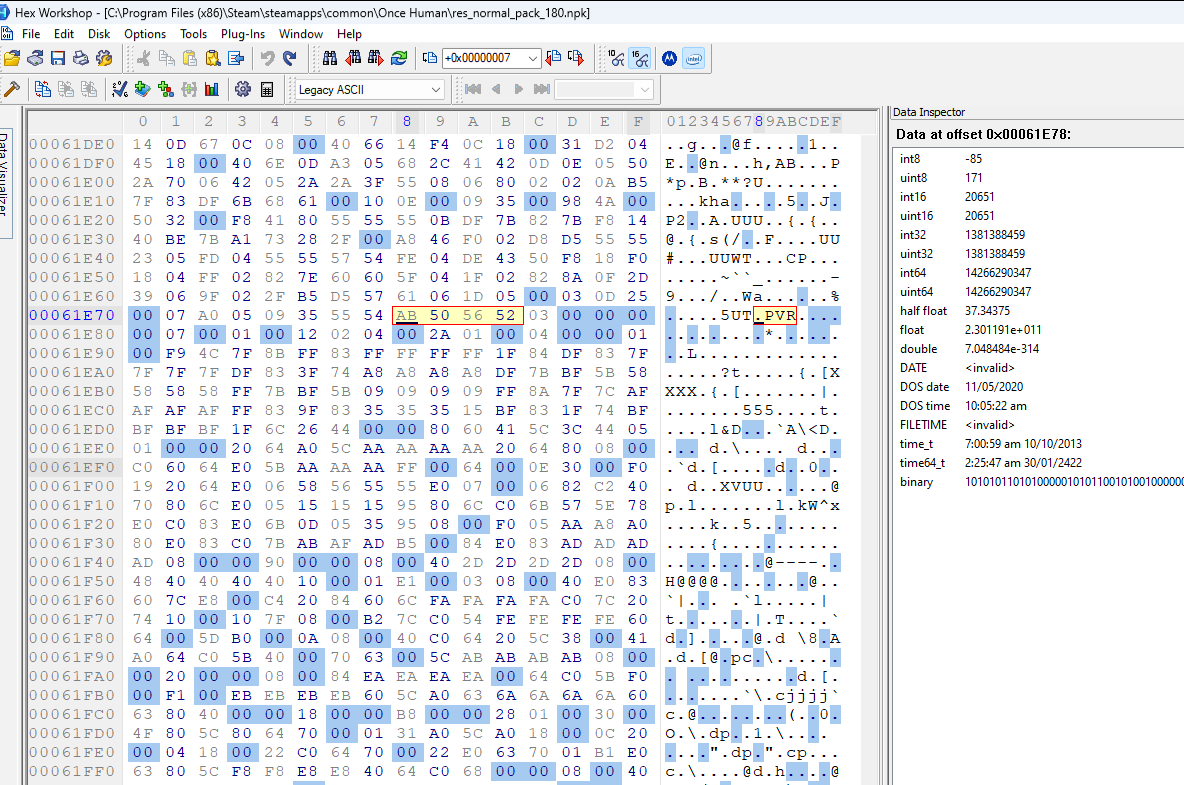
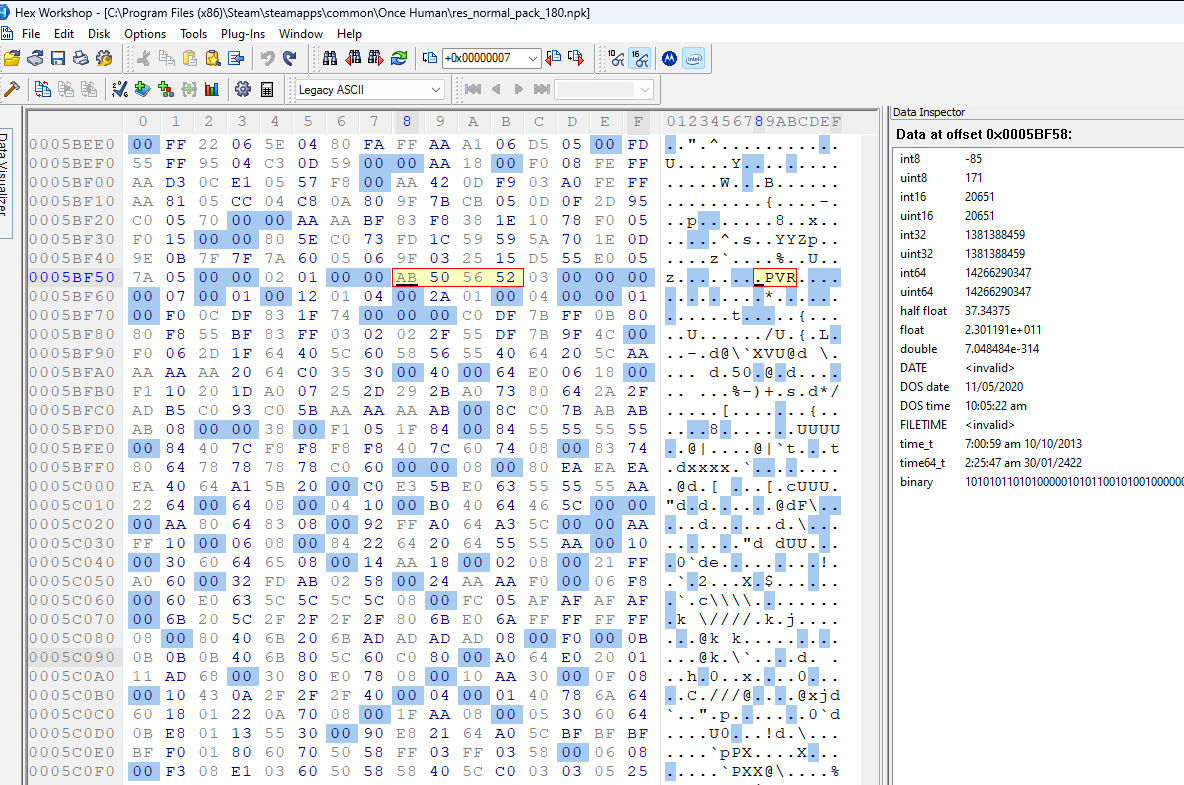
It seems the assumption was right. Every jump seems to point to the file data for a separate file.
Interestingly, the final image above (entry #6) shows the starting point for entry #0 at the far bottom of the image. So file entry #6 is very short. Additionally, looking at the ascii for the file data we see a bunch of tags. Entry #6 is most likely the .pvr.meta file we saw in the file path list.
Data size
Since we now know the start of the file data, we can try and see if there is perhaps a field that tells us the length of the file data.
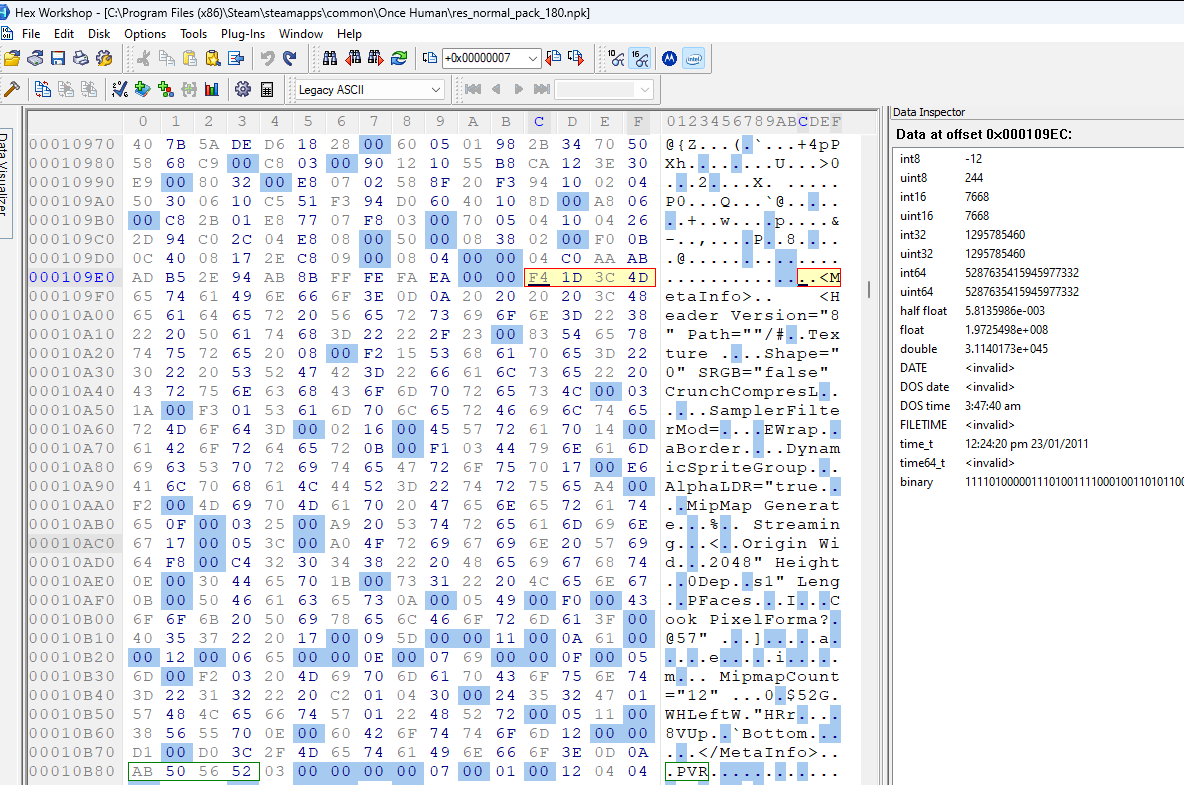
Entry #6 starts at 0xEC 09 01 00 and entry #0, which follows it, starts at 0x80 0B 01 00. Subtracting the two we get 0x194. This corresponds to the value for field #2 for entry #6.
Hex Workshop orders my bookmarks by the address they appear at, so we can easily validate field #2 for the remaining entries.
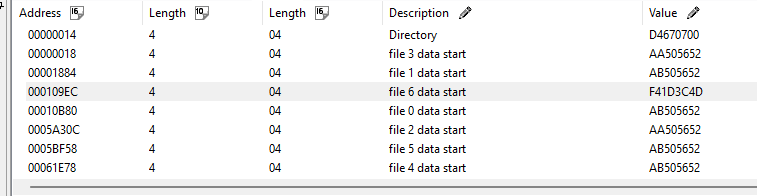
Entry 4 - Entry 5: 0x061E78 - 0x05BF58 = 0x5F20
Entry 5 - Entry 2: 0x05BF58 - 0x05A30C = 0x1C4C
Entry 2 - Entry 0: 0x05A30C - 0x010B80 = 0x04978C
Entry 0 - Entry 6: 0x010B80 - 0x0109EC = 0x0194
Entry 6 - Entry 1: 0x0109EC - 0x001884 = 0xF168
Entry 1 - Entry 3: 0x001884 - 0x000018 = 0x186C
| Entry # | Calculated Size | Expected Size | Difference |
|---|---|---|---|
| 5 | 5F20 |
5F20 |
0 |
| 2 | 1C4C |
1C4A |
2 |
| 0 | 04978C |
04978B |
1 |
| 6 | 0194 |
0194 |
0 |
| 1 | F168 |
F166 |
2 |
| 3 | 186C |
186B |
1 |
It’s a little surprising that they didn’t match, but padding could have been added to make the data align nicely. Looking back at the previous carousel with images of all 7 file data starting points, we can see that some points have null bytes directly before. For example, entry #1 has 1 null byte directly before its starting point. The file before entry #1 (lower offset) is entry #3. From the above table, we can see that entry #3 has a difference of 1 byte between the calculated size and the expected size. This means that there will be one byte of padding following entry #3. So when reading the actual data, we should use field #2 to know how many bytes to read from the starting point (field #1).
We’ve solved the mystery for 2/7 of the fields in the table. But what about the rest? And why do some PVR files start with 0xAA and others with 0xAB? Also, how does the game engine know what name to give the files when they’re extracted?
File paths
To answer the last question, so far, it seems that the order of the table matches the order of the file paths in the NXFN section. Entry # 6 is the meta entry which is the final path in the list. To solidfy this, we can use an observation that the file paths seem to indicate the size of the texture they hold. Let’s make another table:
| Entry # | File Path | Size |
|---|---|---|
| 0 | 1024 | 04 97 8B |
| 1 | 512 | F1 66 |
| 2 | 128 | 1C 4A |
| 3 | 128 | 18 6B |
| 4 | 512 | 01 49 59 |
| 5 | 256 | 5F 20 |
| 6 | meta | 01 94 |
We can see that the sizes line up to roughly the relative order of magnitude we would expect given the file name. So it may be safe to assume that the index in the table structure corresponds to the index in the file path array.
Trying out the file data
I am quite curious about the 0xAA at the start of the PVR files. I decided to copy the raw binary data for the entry #2 into a test.pvr file. When trying to run it through a PVR viewing software, an error is thrown. So something weird is definitely happening here.
Looking at the meta file, we can read most of the text. Some parts are weird but it’s mostly legible. This makes me think that there isn’t encryption on the file data, BUT there may be compression. Still, there are likely hundreds of compression algorithms and I have no idea where to start.
Cheating
I felt very stuck and decided to look online to see if anyone had managed to break into these specific files before me. Since NetEase has many games, their npk file format has been encountered in other games. However, the GRAF may have changed between these games so nothing is guaranteed.
This led to the discovery that the last field in the file table is usually the encryption/compression id. Others had worked out that a value of 2 (which we see for all the files in the small archive) means the files are compressed using LZ4. A value of 3 means they’re compressed using zstd. It may be that there are files in the game’s archives that have different values for field #6 than 2, so I’ll need to test for that when writing my npk extracting program.
But what is LZ4? This prompted me to do some more research on encryption. I learned a bit about the LZ4 algorithm and how it creates a codebook to shorten the message/file on the fly. I found a very helpful video if you’re interested.
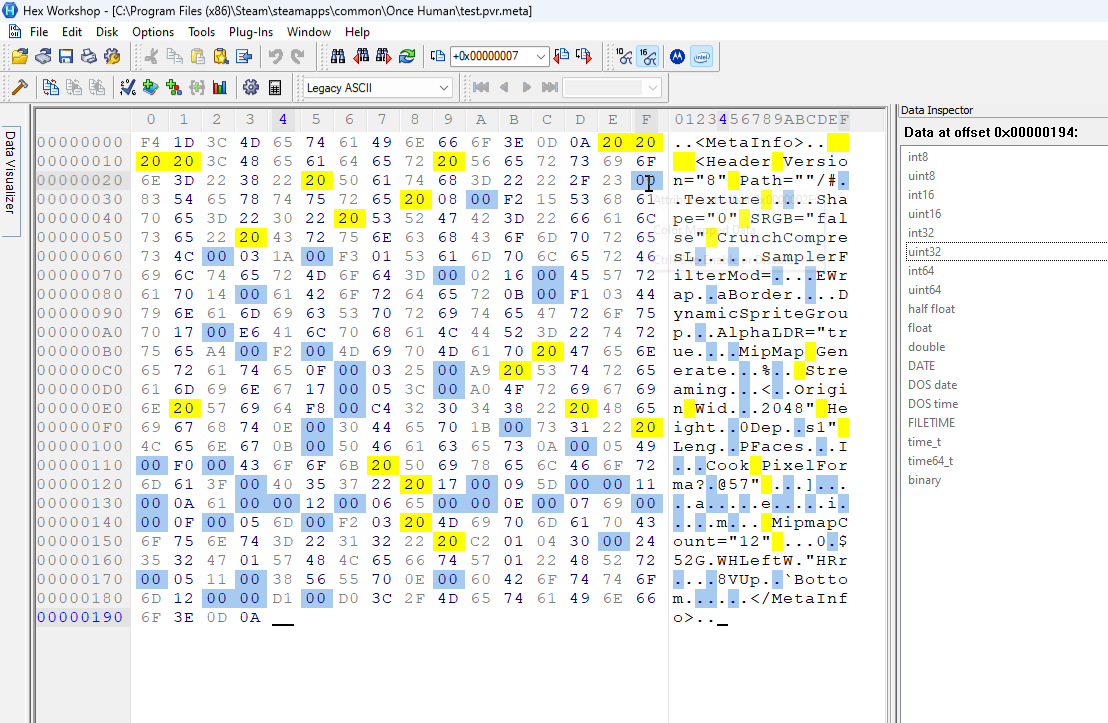
Looking at the meta file I separated (image below), we can see that as the file goes on, it becomes less understandable. This indeed seems to follow the “build a codebook on the fly” idea from the video.
Field #3
While looking back at the large double table of field values I made another observation. Field #3 is always bigger than field #2. Let’s expand our earlier table to include this field!
Note: The large double table stores the value as encountered in the file (in little-endian). The table below shows hex values.
| Entry # | File Path | Size | Field #3 Value |
|---|---|---|---|
| 0 | 1024 | 04 97 8B |
08 00 34 |
| 1 | 512 | F1 66 |
02 00 34 |
| 2 | 128 | 1C 4A |
20 34 |
| 3 | 128 | 18 6B |
20 34 |
| 4 | 512 | 01 49 59 |
02 00 34 |
| 5 | 256 | 5F 20 |
80 34 |
| 6 | meta | 01 94 |
02 36 |
I would normally find it odd that the field #3 value for certain entries (2 & 3; 1 & 4) are the same. However, we know PVR are texture files and thanks to the file path, we know that their size should be the same. So if field #3 is a uncompressed file size, it would make sense that these sizes are the same!
Uncompressing the meta file
Now that we know the compressed size, the uncompressed size, and have an idea for what the compression algorithm might be, we need to try and decompress the file so it’s fully legible.
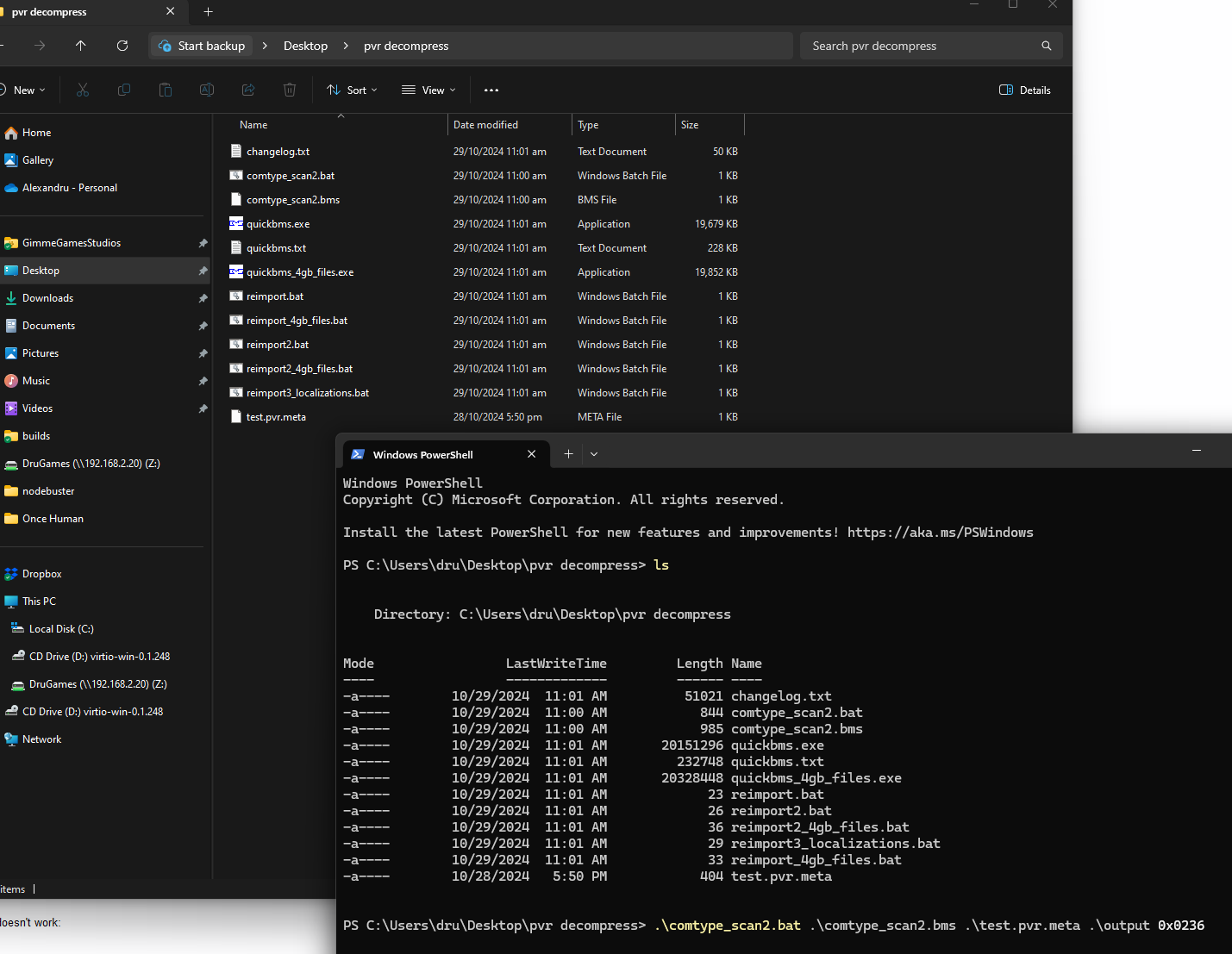
I tried running it through lz4 -d but I got an error about an unrecognized header.
I did a lot more research and honestly, I feel like a lot of this stuff is above my understanding at the moment. I would love to explore compression algorithms more deeply right now, but I have a deadline. So I found a nice QuickBMS script on Reshax (also available on the quickbms website) that brute force decompresses a file using all the algorithms supported by QuickBMS. QuickBMS is a program that uses script files to extract game archives. The brute force script outputs a file after running each decompression algorithm and if I get a file that makes sense, that’s the algorithm that was used.
Sometimes while running, the script gets stuck. What happens here is that the decompression algorithm enters a never ending loop and keeps adding bytes to a file. When this happens on a small file, we know immediately that that was not the compression algorithm used. We can cancel that algorithm and continue with
ctrl-c > n.
I ran the script on the .pvr.meta file data that I isolated from the small archive. Once it finished, it ran over 850 known decompression algorithms. It only got stuck a handful of times. To filter out some of the files I opened the output folder in neovim and live-grepped “MetaInfo”. Of the over 850 files, with over 1 GB of decompressed files, only two files had text that made sense: LZ4.dump and LZ77EA_970.dmp. The other files had the opening MetaInfo tag and then garbage following it. So in the end the compression was LZ4. Or at least the LZ4 that is implemented in QuickBMS.
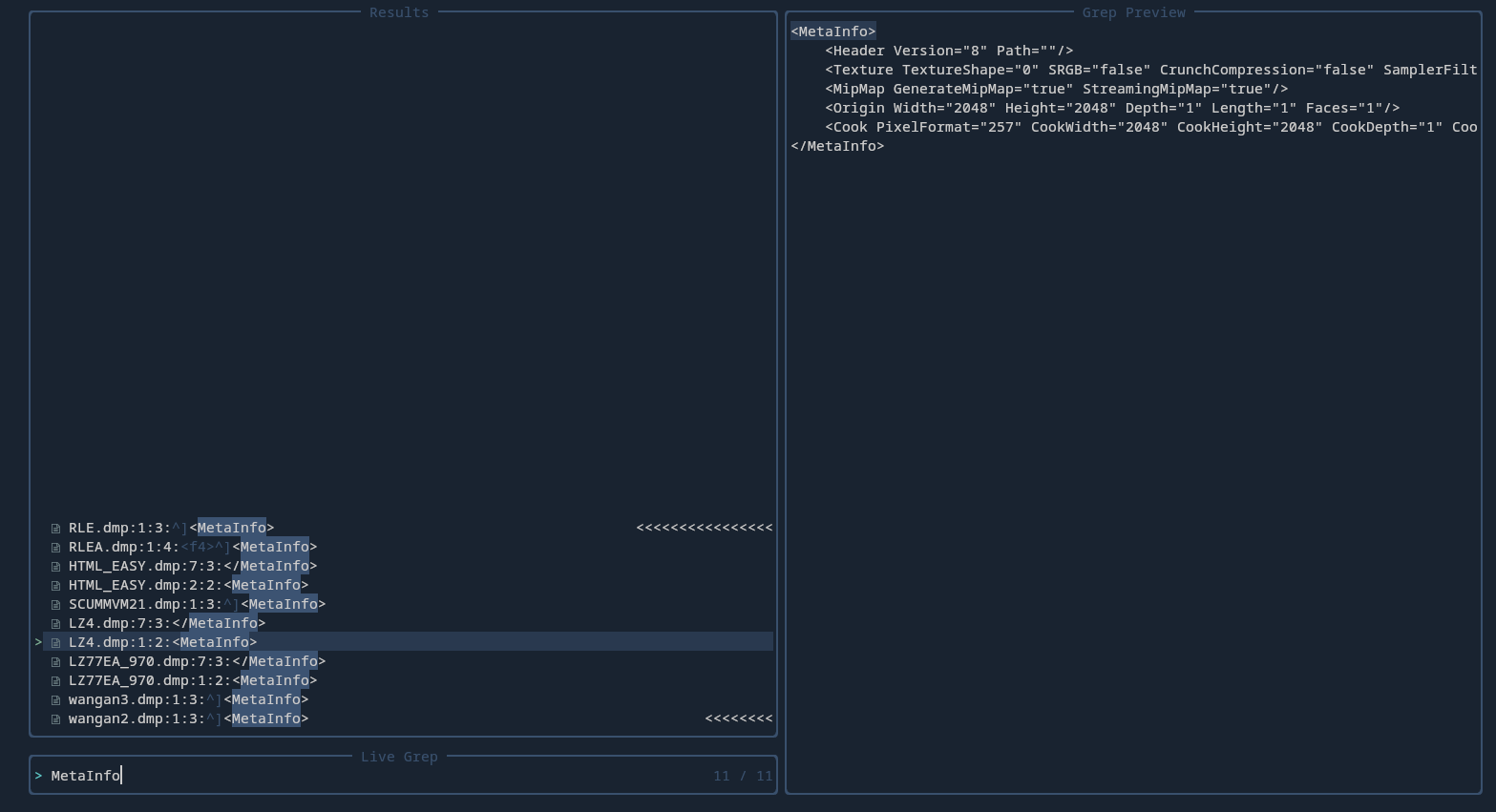
Uncompressing the pvr file
Looking at the brute force bms script (comtype_scan2.bms) and the quickbms documentation I created my own BMS script to run on extracted file data. The plan is to run this on the pvr files and see if it produces something that makes sense.
My bms file:
quickbmsver 0.5.4
if QUICKBMS_ARG1 == ""
print "you must provide the uncompressed size"
cleanexit
endif
get ZSIZE asize
set SIZE long QUICKBMS_ARG1
comtype LZ4
set NAME string "out.pvr"
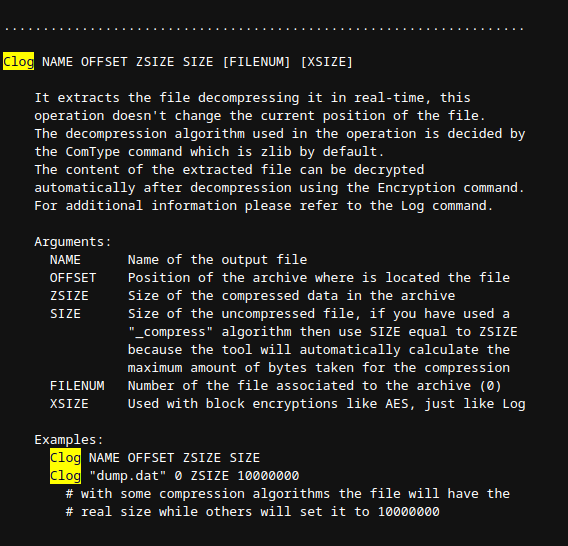
clog NAME 0 ZSIZE SIZE
I ran this with:
.\quickbms.exe -a "0x2034" .\once_human_single_file.bms test.pvr .
The -a means pass this as an argument to the BMS script. Then we pass in the bms script, the file to decompress, and the output folder to quickbms.
Running this in a PVR viewer shows the following:
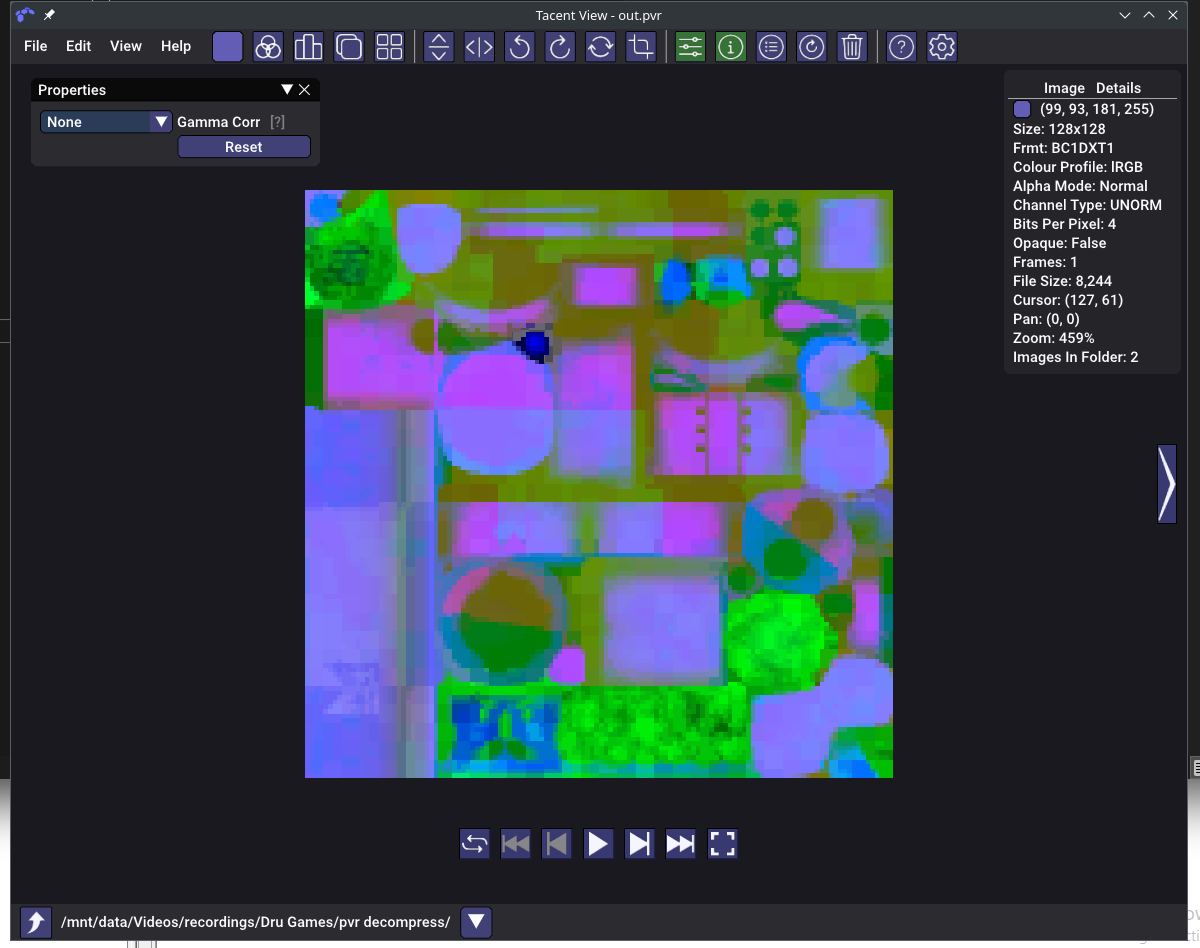
The file is expected to be 128x128, which it is. There are some clear patterns in the file, but I have no idea what this could be.
For sanity, I ran the decompression again with LZ77EA_970. The output looked the same.
Extracting everything!
I think we’re at the point where we can try and decompress a full archive. We know how to find file paths, how to find file data, and how to decompress that data.
Since I now understand the full archive structure I can comfortably use this bms script I found (also below) for extracting once human beta files. In the future, if such a script doesn’t already exist, I’d be very comfortable writing my own. But right now, why reinvent the wheel?
# ================================================================================
# Once Human (Beta)
# NPK archive extract
# QuickBMS script by DKDave, 2023 - updated 3 January 2024
# ================================================================================
# Should work for older NetEase games with the same archive format
IDString "NXPK"
Get FILES Long
Goto 0x14
Get ENTRY Long
XMath NAMES "ENTRY + (FILES * 0x1c) + 0x10"
For A = 0 < FILES
Goto ENTRY
Get MISC1 Long
Get OFFSET Long
Get ZSIZE Long
Get SIZE Long
Get MISC2 Long
Get MISC3 Long
Get COMP_TYPE Long
Goto NAMES
Get FILENAME String
SavePos NAMES
If ZSIZE <> SIZE # Compressed files
If COMP_TYPE = 2
ComType LZ4
CLog FILENAME OFFSET ZSIZE SIZE
ElIf COMP_TYPE = 3
Comtype ZSTD
CLog FILENAME OFFSET ZSIZE SIZE
Endif
Else # Uncompressed files
If ZSIZE > 0
Log FILENAME OFFSET ZSIZE
Endif
Endif
Math ENTRY + 0x1c
Next A
We can see that the script identifies the archive by its magic, saves the number of files in the archive, jumps to 0x14 which contains the pointer to the file table. Then it calculates the starting position of the file path array. Then for each file, it grabs the file data offset, the compressed size and the uncompressed size, the compression type and finally the file path. It tests if compression was done and if it was, it decompresses it based on the compression type. It then continues until all the files in the archive are done.
To do this over all the npk files in once human, we need a batch file that calls quickbms with this bms script.
FOR /R %%G in ("*.npk") DO (
quickbms %1 "%%G" %2
)
REM arg_1 : bms file
REM arg_2 : output dir
REM run in game dir
Locating the model
At this point the scope of this blog entry has been fully fulfilled. However, for completeness I will write a few more sections.
To preview the models I used the recommended Noesis program along with a python script developed explicitly for once human (beta). The script opens up the mesh file, locates any submeshes, assembles everything together, then texturizes it using information in the GIM file. I should mention that there were some issues with the py script. There were messages that were printed but never output to any console. The way I solved that was by calling noesis.logPopup() at the very start. Then you could easily see all the error messages.
The model I’m looking for is the morphic crate toy. I used Search Everything to try and find it but neither morphic nor crate found what I was looking for. While browsing the files directly I found an interesting path: environment\dynamic_objects\buildingsystem\furniture\toy. It contained all sorts of toy models that I haven’t seen. These could be premium toys or toys that are not used in the game as of yet. Very interesting!
Finally, after a lot more browsing I found my target mesh in environment\dynamic_objects\buildingsystem\furniture\c_monsterpose

3D printing
The rest is relatively easy. Export the mesh file into an obj. Import it into ChituBOX, add supports and print! Here is the support structure, the printed result, and the painted result (to be updated once printed):




Disclaimer
I should mention that I will NOT print / sell this or any other model in the game data (please don’t ask). All models are the property of NetEase. I underwent this whole project to give my buddy something they would really love from a game they’ve already spent way too much money on (imo).